OmniHuman-1: ByteDance's AI Model for Ultra-Realistic Human Video Generation
Developed by ByteDance, this framework brings static images to life by adding natural movements, gestures, and expressions—all from simple inputs like audio or video.


Imagine creating lifelike videos from just a single image. With OmniHuman-1, that’s now a reality. Developed by ByteDance, this framework brings static images to life by adding natural movements, gestures, and expressions—all from simple inputs like audio or video.
What is OmniHuman-1?
OmniHuman is a model by Bytedance that can turn a single image of a person into a video with realistic movement. Whether it's a portrait, half-body, or full-body shot, it can animate the image with lifelike gestures, expressions, and fluid motion. It works by combining an image with motion signals, like audio or video, to create natural video content.
The model uses a special method of training that mixes different types of motion inputs, which helps improve the accuracy and realism of the generated video. This approach allows it to overcome limitations that have been common with similar technologies in the past, such as a lack of high-quality data

OmniHuman-1 Guide for Developers
OmniHuman-1 is an end-to-end multimodality-conditioned human video generation framework designed to generate realistic human videos from a single image and motion signals, such as audio, video, or both. This end-to-end system brings static images to life, capturing natural movements and expressions with remarkable precision.
OmniHuman-1 introduces a multimodality motion conditioning mixed training strategy, allowing the model to learn from a diverse set of motion inputs. This approach helps overcome the common challenge of limited high-quality training data, ensuring smooth and lifelike animations.
Whether for digital avatars, virtual influencers, or creative storytelling, OmniHuman-1 sets a new standard for AI-driven human video generation.

Key Features of OmniHuman-1
Realistic Lip Sync and Gestures
Accurately synchronizes lip movements and gestures with speech or music, enhancing the natural appearance of avatars.
Multimodality Motion Conditioning
Integrates images with motion signals, such as audio or video, to generate realistic human videos.
Versatility Across Formats
Supports multiple aspect ratios to accommodate different content formats and platforms.
Supports Various Inputs
Handles portraits, half-body, and full-body images seamlessly. Works with weak signals, such as audio-only input, producing high-quality results.
High-Quality Output
Produces high-quality videos with precise facial expressions, natural gestures, and seamless synchronization.
Examples of OmniHuman-1 in Action
OmniHuman-1 model is designed to create highly realistic videos from a single image and motion signals, such as audio or video. Its advanced capabilities make it suitable for various applications, from singing performances to animated content.
1. Singing Animation
OmniHuman-1 accurately translates music into expressive movements and facial expressions:
- Gestures align with the rhythm and style of the song.
- Facial expressions reflect the mood and tone of the music.This makes it ideal for generating AI-driven music videos and virtual performances.
2. Talking Avatars
The model excels at generating natural lip-syncing and body language for talking avatars, making it useful for:
- Virtual influencers who engage audiences on social platforms.
- Educational content, such as AI-driven tutors or narrators.
- Entertainment and storytelling, where animated characters need realistic speech and expressions.OmniHuman-1 supports various aspect ratios, ensuring compatibility across platforms.
3. Cartoons and Anime
Beyond human figures, OmniHuman-1 can animate:
- Cartoon characters with fluid expressions and gestures.
- Animals that mimic natural or stylized movement.
- Artificial objects, expanding possibilities for creative projects.This capability makes it a valuable tool for animated films, interactive content, and gaming.
4. Portrait and Half-Body Animation
OmniHuman-1 maintains high realism even in close-up shots, capturing subtle facial details like:
- Smiles, frowns, and other microexpressions.
- Hand gestures and head movements for enhanced expressiveness.This makes it well-suited for personalized avatars and digital human representations.
5. Video-Based Motion Transfer
OmniHuman-1 can replicate motion from a reference video to create realistic animations:
- A recorded dance performance can be used as input, generating a new video with a different character performing the same moves.
- Combining both audio and video signals allows for full-body animations where gestures and speech movements are precisely synchronized.
With its ability to generate photorealistic and animated content, OmniHuman-1 is paving the way for more dynamic, AI-powered video creation across multiple industries.
How to Use OmniHuman-1 on Eachlabs?
Step 1: Input
On Eachlabs, to begin, you provide a single image of a person—this could be a photograph of yourself, a celebrity, or even a cartoon character. Next, you add a motion signal. This could be an audio clip of someone singing, talking, or even a reference video of a person performing certain actions.

Step 2: Processing
OmniHuman uses a technique called multimodal motion conditioning, which allows the model to interpret motion signals and convert them into realistic human movements. For example:
- When the audio is a song, the model generates gestures and facial expressions that correspond to the rhythm and style of the music.
- When the audio is speech, OmniHuman synchronizes lip movements and gestures with the spoken words.
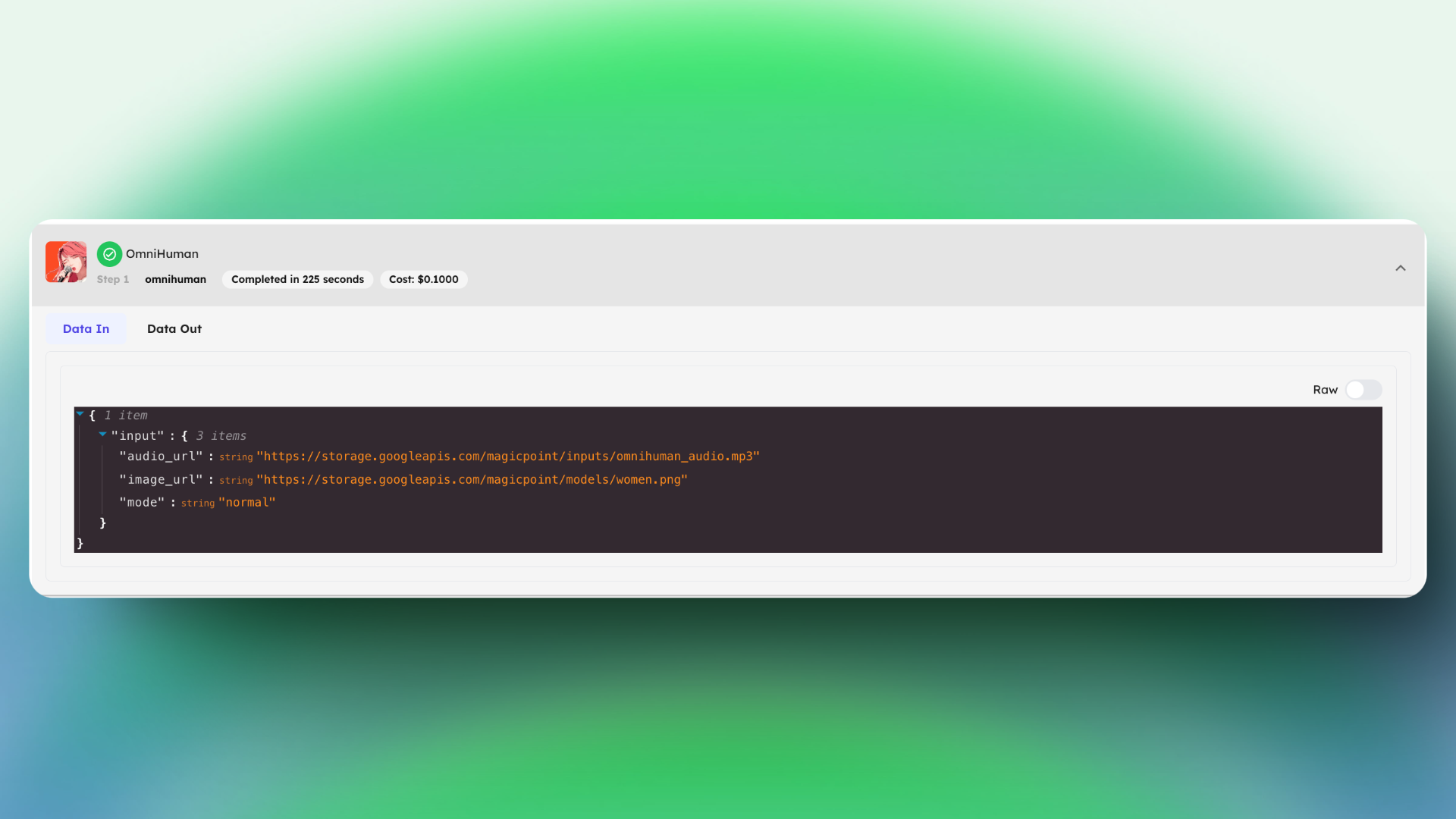
Step 3: Output
The result is a high-quality video that looks like the person in the image is actually singing, talking, or performing actions described by the motion signal. OmniHuman excels even with weak signals like audio-only input, producing realistic results.
Here is another example on Eachlabs
Inputs:
image_url:

audio_url:
Output:
Conclusion
Our partner ByteDance's OmniHuman model, a comprehensive framework for generating human videos from a single image and motion signals (e.g., audio, video, or both). OmniHuman utilizes a mixed-data training strategy with multimodal motion conditioning, capitalizing on the scalability of diverse data to address the challenge of limited high-quality data in previous methods. This innovative approach significantly outperforms existing techniques, enabling the generation of highly realistic human videos, even from weak signals, particularly audio. OmniHuman supports images of any aspect ratio—whether portraits, half-body, or full-body—delivering lifelike, high-quality results in various contexts.